LLM이란 무엇일까?
1. Language Model
- LM(Language Model)이란 (과거에) 일반적으로 단어의 시퀀스(문장)에 대해, 다음에 나타날 단어가 어떤것인지를 예측하는 모델을 의미함
- LM의 발전 과정은 크게 다음과 같이 4가지 단계로 나눌 수 있음
1.1 Statistical Language Model(SLM)
- 1990년대에 주로 연구가 이루어 졌으며, 통계적 학습(statistical learning)에 기반을 두고 있음
- 대표적으로 $n$-gram LM이 있으며, 예측에 사용할 앞 단어들의 개수를 정하여 모델링 하는 방법
- SLM의 단점은 $n$-gram 설정에 따라 차원이 커지는 문제(curse of dimensionality)가 발생하고, 모델의 크기가 매우 커져 단어에 대한 확률을 추정하기가 어렵다는 단점이 있음
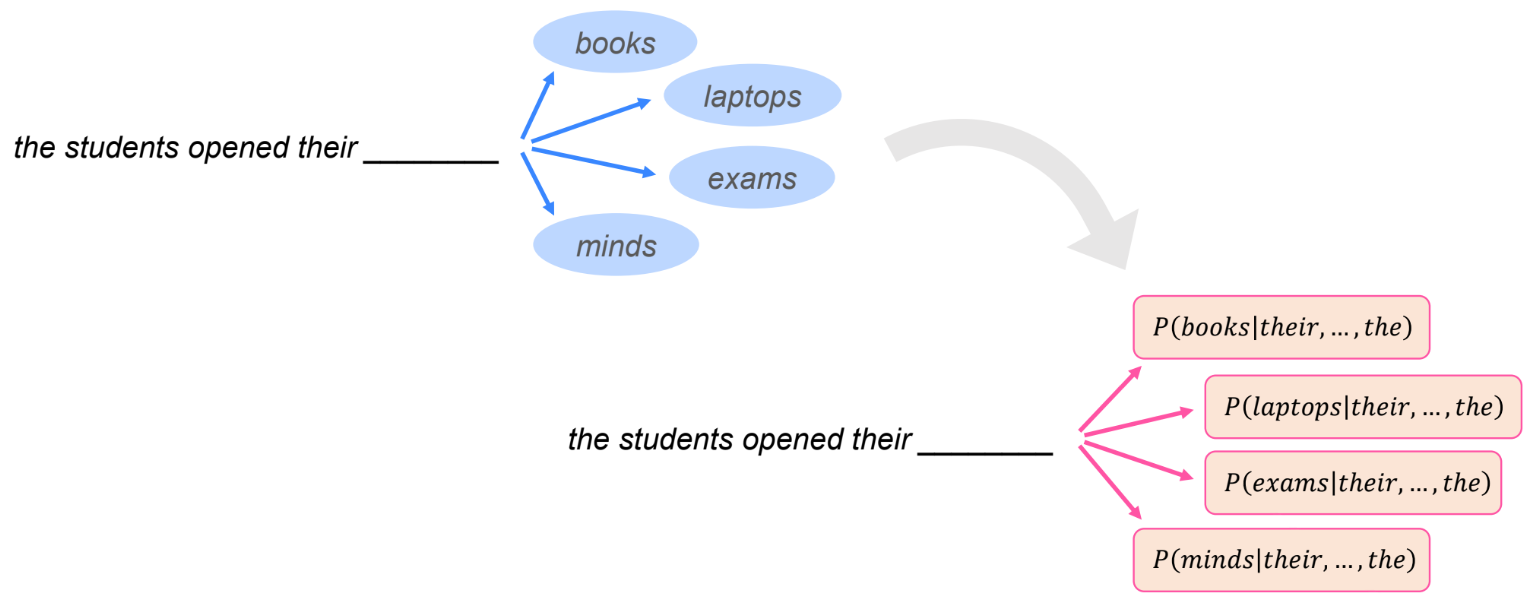
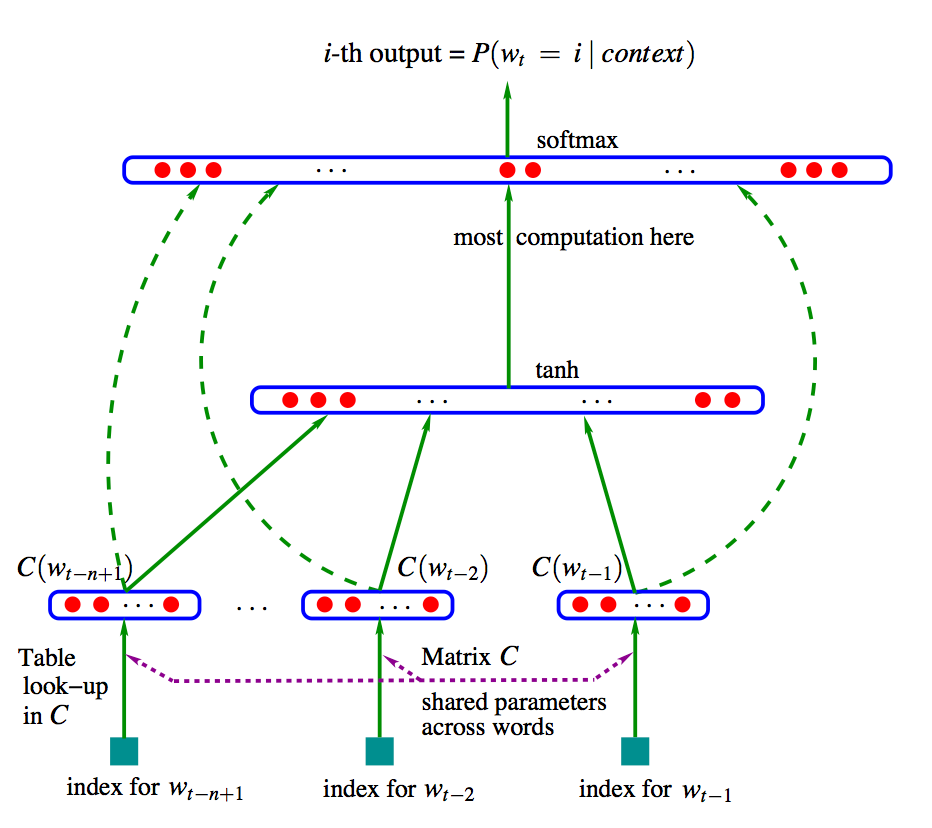
1.2 Neural Language Model(NLM)
- Neural Network를 LM에 적용하여 SLM의 문제점을 해결함
- 초기에는 NNLM(Bengio et al, 2003)이 있으며, word2vec 그리고 RNN을 적용한 LM들이 등장함
- NLM 때 부터 단어에 대해 distributed representation을 사용함
1.3 Pre-trained Language Model(PLM)
- biLSTM 기반인 ELMo를 시작으로 Transformer 기반의 BERT, GPT 등 다양한 PLM들이 등장하기 시작함
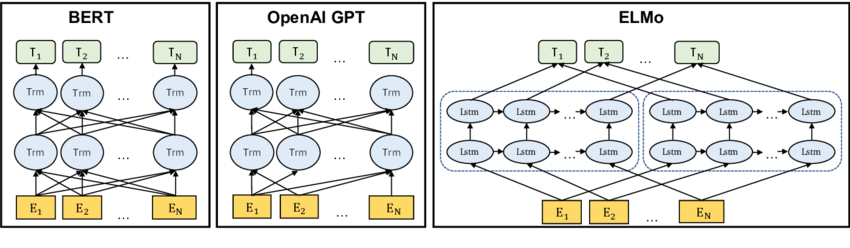
- 이 시기부터, Language Modeling의 패러다임이 바뀌었다고 해도 과언이 아닐 정도로 텍스트 데이터 전처리부터 시작하여 학습 방법 그리고 모델링 등 많은 것들이 바뀜
- 텍스트 전처리: BPE(Byte-Pair Encoding)와 SP(Sentence-Piece) 등을 사용하여, 각 언어별로 필요했던 Tokenizer(e.g Mecab, NLTK 등)가 더이상 필요하지 않게됨
- 학습 방법: MLM(Masked Language Model), NSP(Next Sentence Prediction) 등을 이용한 Pre-training과 특정 태스크에 대해 Fine-Tuning으로 이루어짐
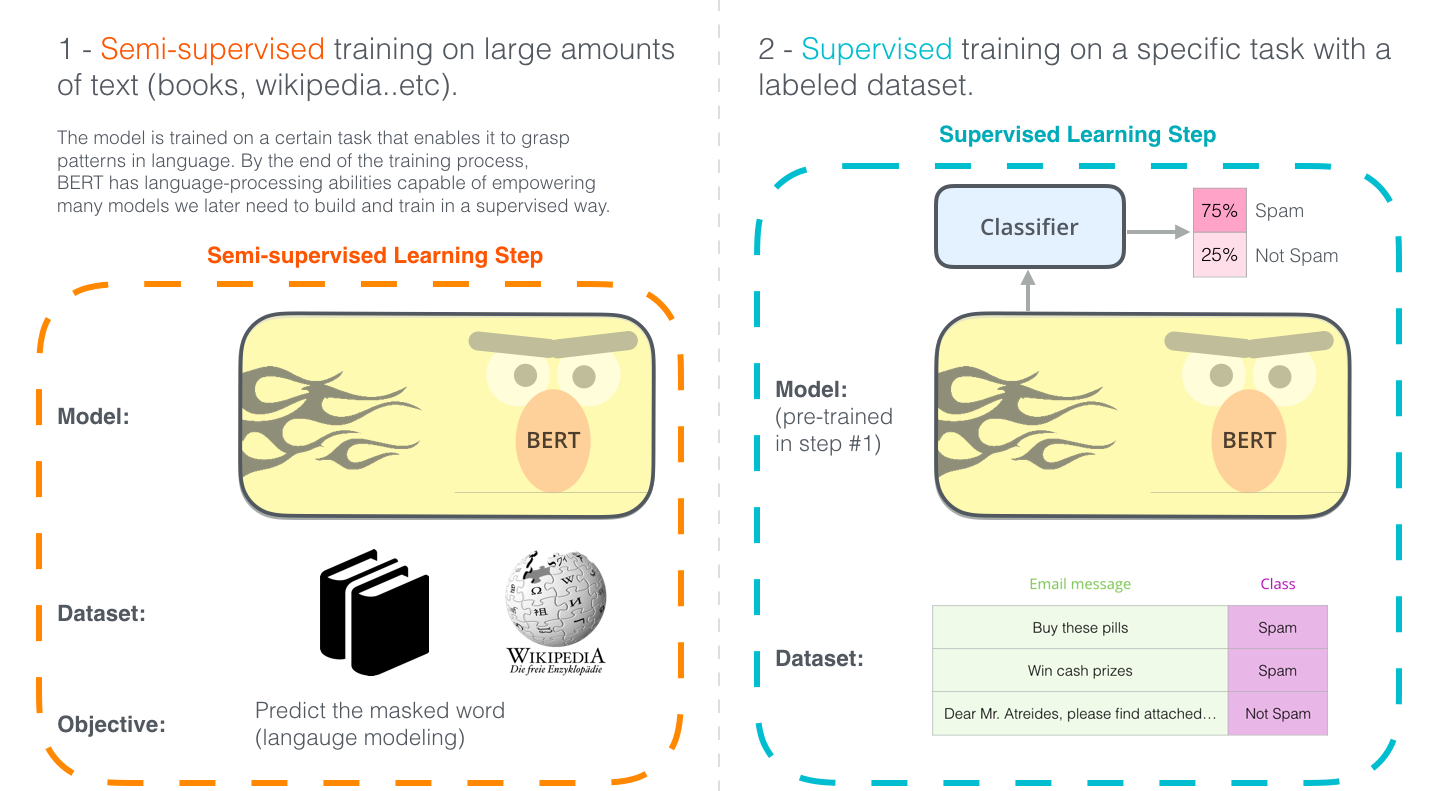
1.4 Large Language Model(LLM)
- LLM(Large Language Model)은 말 그대로 모델의 크기가 매우 매우 큰 PLM을 의미함
- 이처럼 PLM을 확장(e.g. 모델 또는 데이터 사이즈) 시킬 경우 downstream 태스크에서 성능이 향상되는 경우가 많다는 사실을 발견하게 됨 → scaling law를 따름
- 또한, 이전에는 학습하지 않은 Task들을 해결할 수 있는 Emergent Ability가 발생하기도 함
- 이러한 Emergent Ability는 작은 PLM에서는 발생하지 않지만 LLM에서는 발생함
- LLM의 성능은 선형적으로 증가하지 않고 특정 크기를 넘을 때마다 크게 증가함
- 따라서, Emergent Ability가 LLM과 기존 PLM을 구별하는 가장 큰 특징이라고 할 수 있음
- 2019년 T5를 시작으로, 2020년 GPT-3, 2021년 HyperCLOVA, 2022년 ChatGPT, 2023년 LLaMA 등 다양한 LLM이 쏟아져 나오고 있는 상황
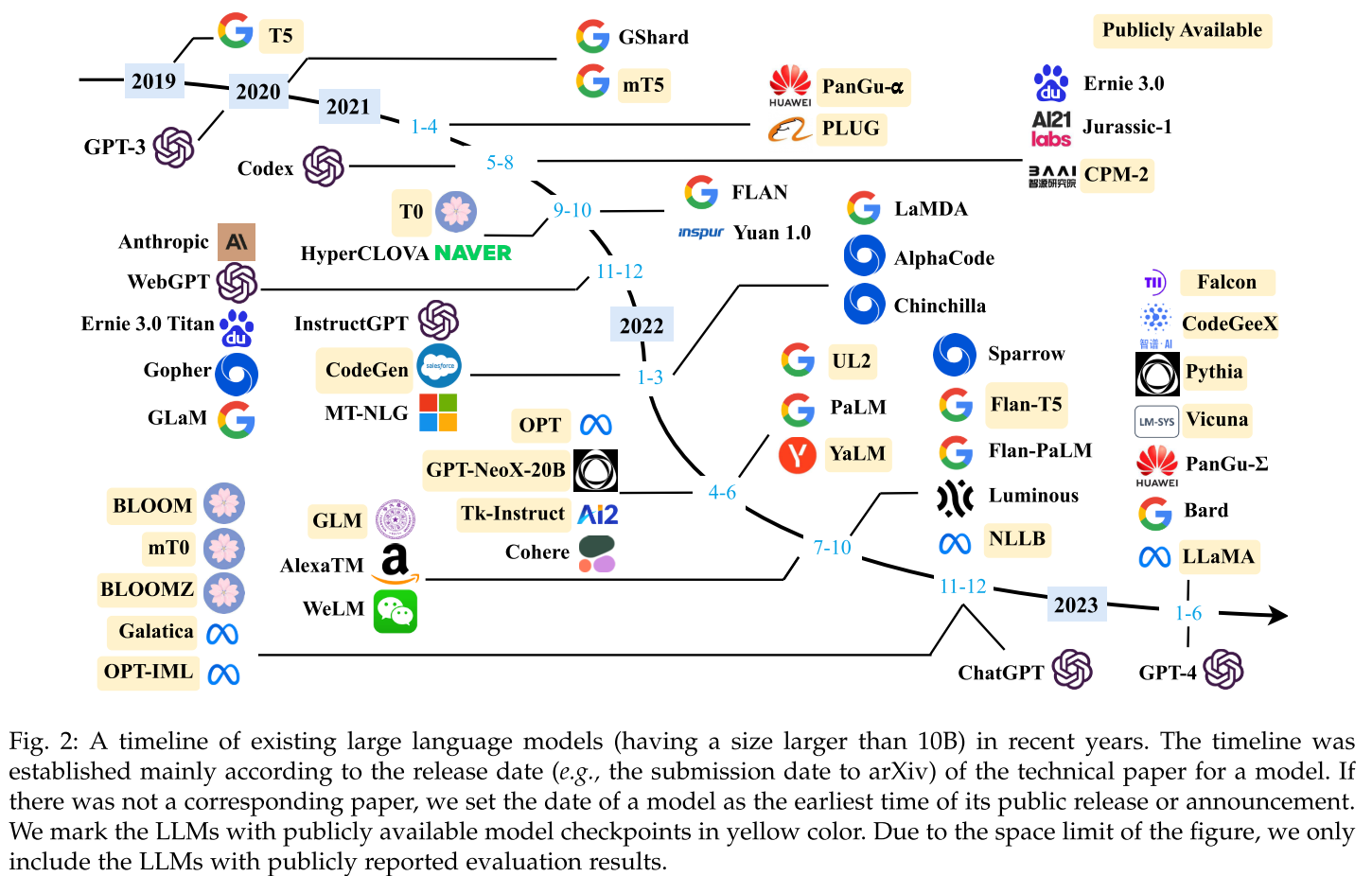
2. Backgroud for LLMs
- 일반적으로 LLM들은 Transformer 구조를 기반으로 하며, 파라미터 수는 수십억( >1B) 이상인 모델을 의미함
- 또한, 학습 시키는 텍스트 데이터의 양은 TB 이상의 대규모 데이터로 LLM을 학습 시킴
2.1 Scaling Laws for LLMs
-
현재의 LLM 또한 기존의 PLM의 pre-training(e.g. language modeling)과 같은 방식으로 pre-training이 이루어짐
-
PLM의 차이점은 LLM은 모델 크기($N$), 데이터 크기($D$), 총 연산($C$, 아마도 학습 시간을 말하는 듯)을 매우 크게 늘린 다는 것
-
즉, LLM은 Scaling Law를 따름
-
이처럼 모델, 데이터, 연산을 크게 늘림에 따라 성능이 크게 향상된 다는 것은 실험적으로 알게 되었는데, 대표적인 Scaling Law로는 KM scaling law 와 Chinchilla sacling law가 있음
-
KM scaling law:
- 2020년, OpenAI 팀에서 LLM은 모델 크기($N$), 데이터 크기($D$), 학습 연산량($C$), 이렇게 3가지 요인에 따라 멱법칙(power-law) 관계있음을 정량적으로 밝혀냄
- $N$과 $D$의 크기가 같이 커질 경우 성능 또한 향상되며, $D$가 고정될 경우 $N \times 8$ 또는 $N$이 고정될 경우 $D \times 5$ 정도는 되어야 함
- $N$이 큰 모델은 더욱 적은 데이터(data efficient), 적은 optimization steps로 비슷한 수준의 성능에 도달함
- 동일한 $C$에서 $N$과 $D$의 제약이 없을 때, 아주 큰 모델에서 적게 훈련하는 것이 가장 성능이 좋음
- 아래의 식에서 $L(\cdot)$ 은 cross entropy loss를 의미함:
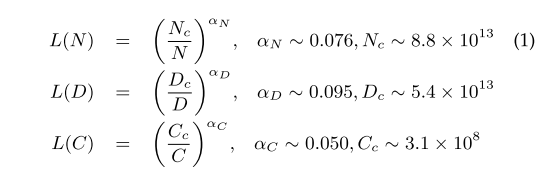
-
Chinchilla scaling law:
-
DeepMind에서 공개한 Chinchilla LLM을 학습시킬 때, 제한된 Compute Budget(FLOPs) 내에서 최고의 성능을 내기 위한 최적의 모델 및 학습 데이터 크기 선정에 대한 scaling law를 제안함

-
2.2 Emergent Abilities of LLMs
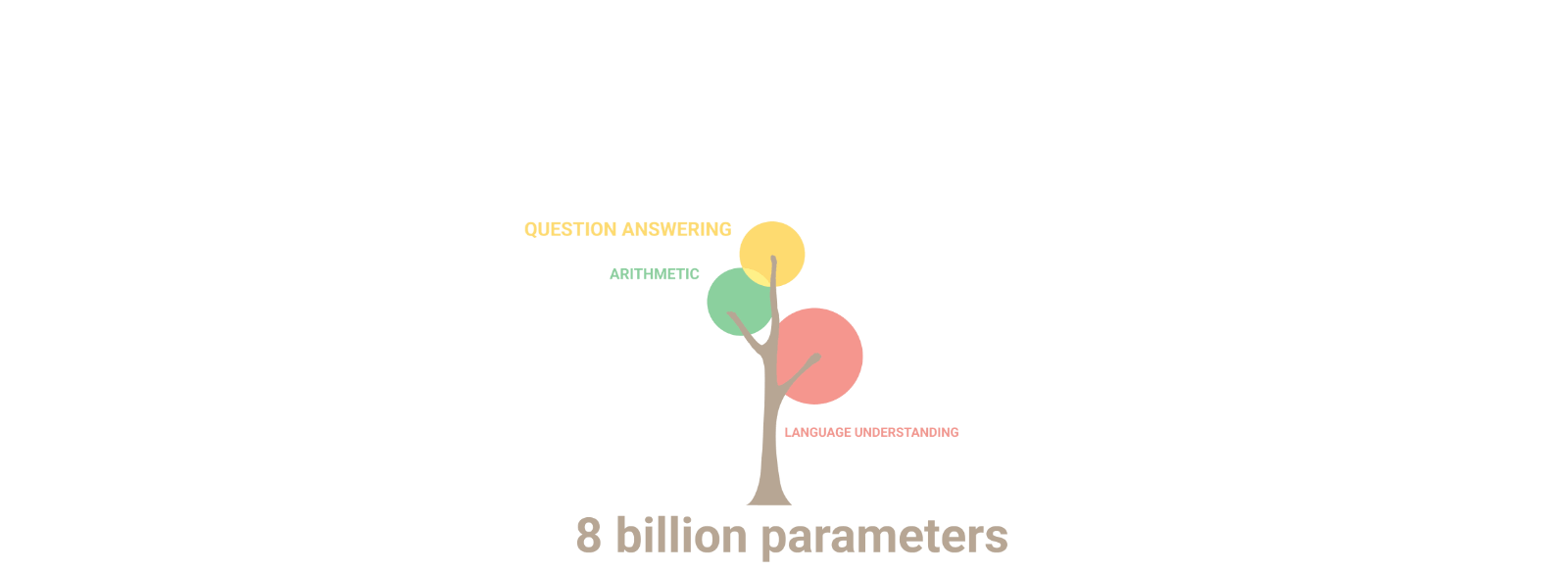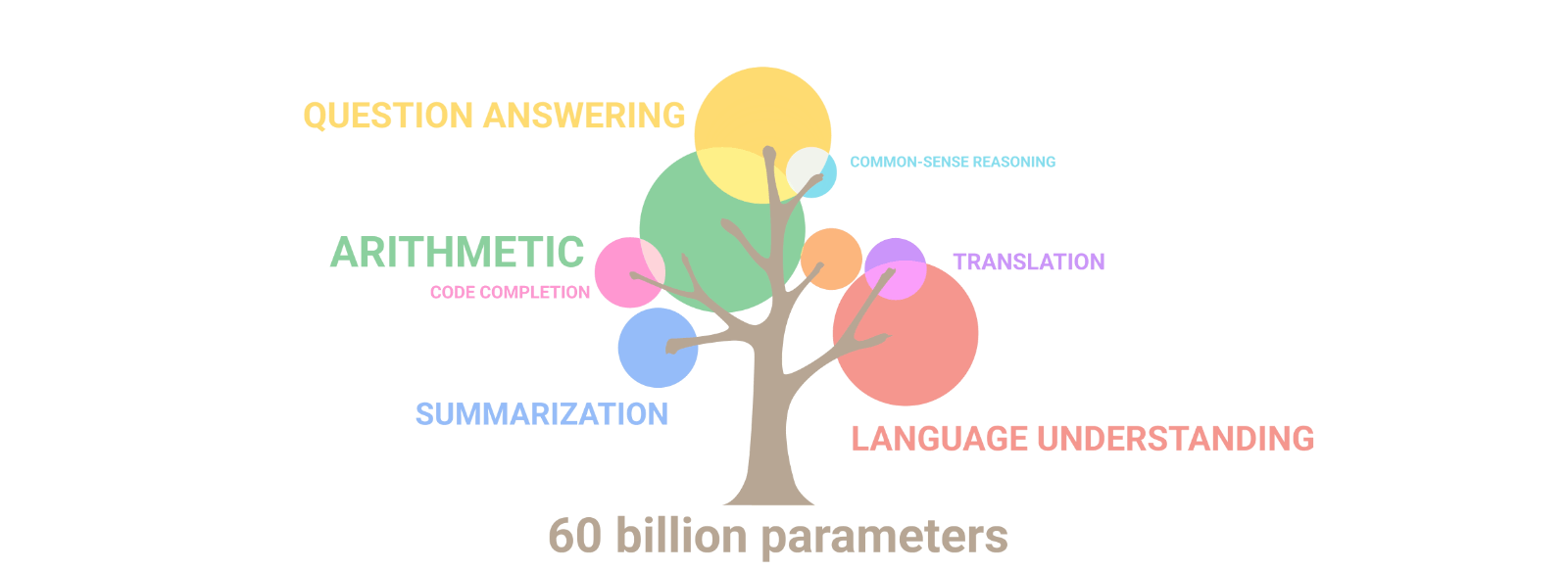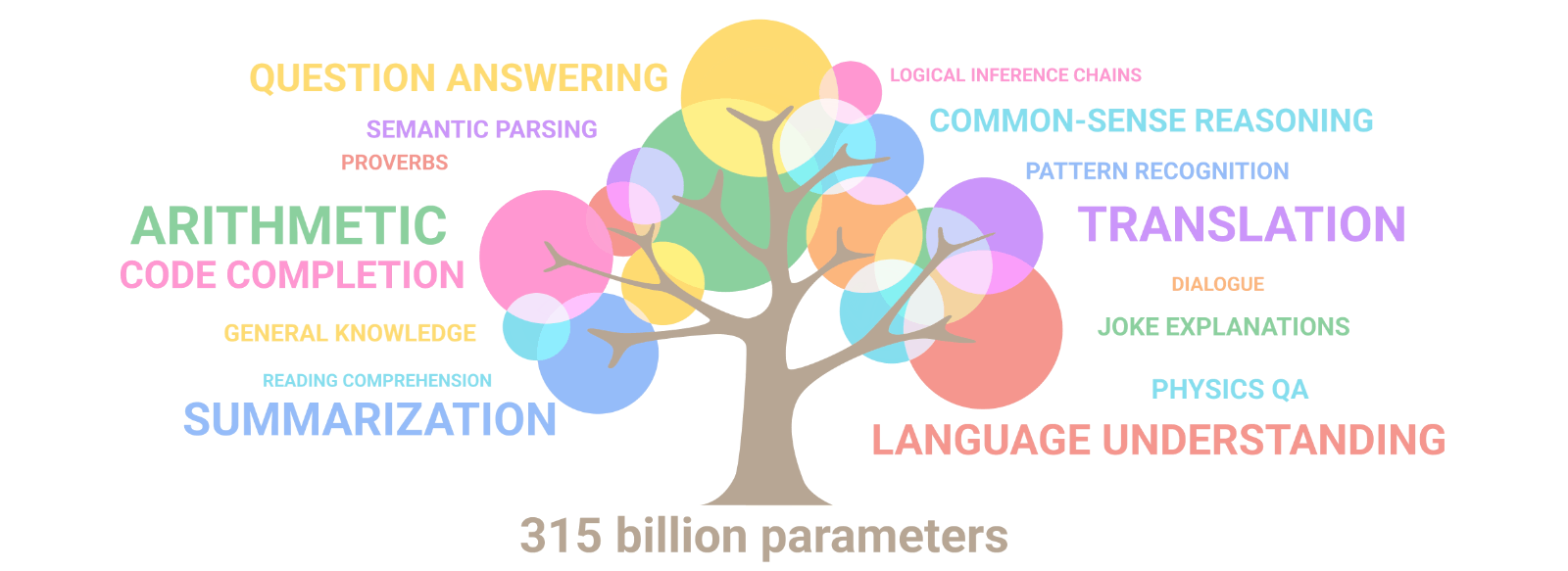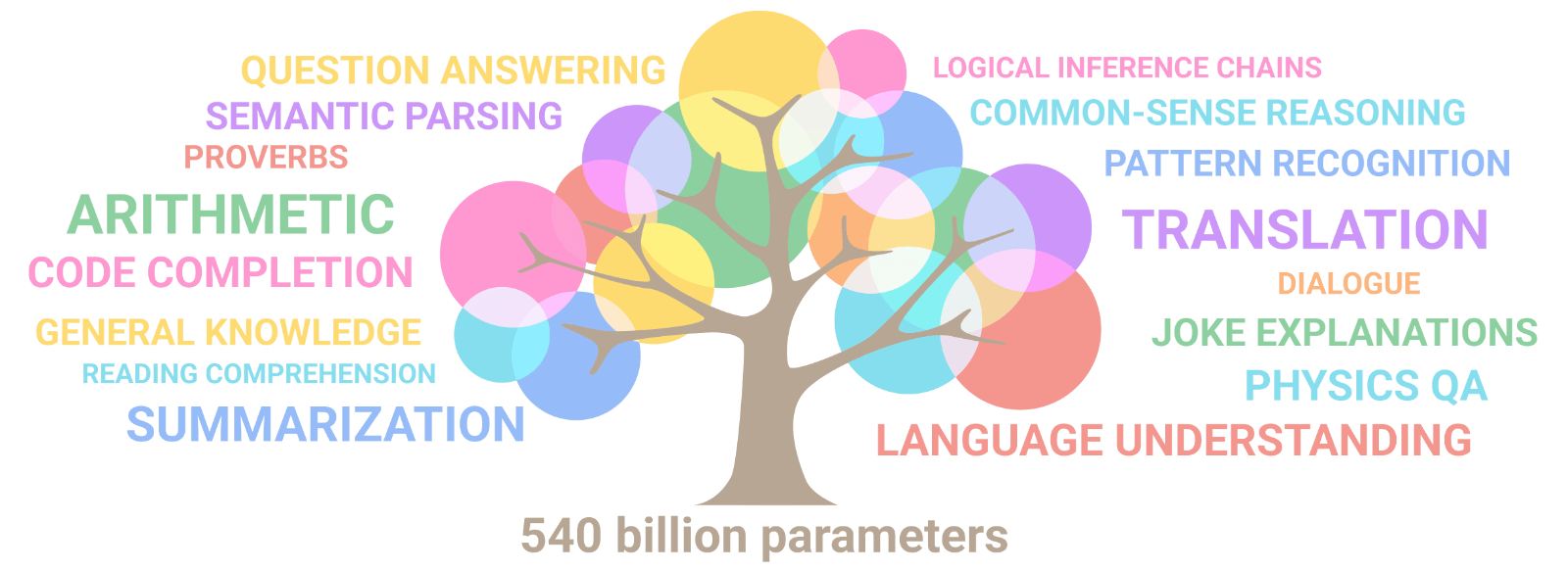
- Emergent Abilities는 해당 논문(link)에서 다음과 같이 정의함:
- “The abilities that are not present in small models but arise in large models”
- 이러한 Emergent ability가 PLM과 LLM을 구분짓는 특징 중 하나라고 할 수 있음
- LLM에서 나타나는 대표적인 3가지 Emergent Abilities들은 다음과 같음
- In-context learning → Prompt Engineering
- Instruction Following → Instruction Tuning
- Step-by-step reasoning → CoT(Chain of Thought) Prompting
2.3 Key Techniques for LLMs
- 최근 들어, NLP 분야에서의 연구는 LLM의 성능을 크게 향상 시킬 수 있는 여러가지 방법들을 제안하는 트렌드로 바뀌고 있음
- LLM의 성능을 끌어 올릴 수 있는 몇 가지 중요한 방법들은 다음과 같음
- Scaling:
- 모델의 크기가 커질수록 성능은 향상됨
- GPT-3와 PaLM은 각각 175B과 540B의 크기를 가지는 LLM 모델임
- 하지만, 컴퓨터 리소스의 한계로 인해 엄청난 크기의 LLM을 학습시키기에는 무리가 있음 (구글, MS 는 제외…)
- 따라서, 효율적으로 학습시키기 위해 Scaling law를 따르도록 설계하는 것이 좋음
- Training:
- LLM의 크기는 기본적으로 10B이 넘어가기 때문에, 현재 나와있는 단일 GPU로 학습시키기에는 불가능함
- 따라서, Multi-GPU를 통한 분산 학습이 필요한데 학습시키기에 매우 까다로움
- 최근에는 분산 학습을 지원하기 위한 DeepSpeed(Microsoft), Megatron-LM(Nvidia) 와 같은 최적화 프레임워크를 사용하여 학습함
- Ability eliciting:
- 최근 LLM의 Emergent를 끌어내기 위해 다양한 방법들이 제안 되고 있음
- CoT(Chain-of-Thought) Prompting을 통해 중간 추론 단계를 포함 시킴으로써, 더 복잡한 추론 과제를 해결할 수 있음
- 또한, Instruction Tuning을 통해, 학습할 때 본적 없는 태스크에 대한 LLM의 일반화 성능을 향상 시킬 수 있음
- Alignment tuning:
- LLM은 다양한 텍스트 데이터(e.g. Common crawl) 들을 사용하여 pre-training 되기 때문에 고품질 데이터와 저품질 데이터 모두 포함 되어 있음
- 그렇기 때문에, 유해하거나 편향적인 데이터가 포함되어 있을 가능성이 큼
- 이러한 문제를 해결하기 위해 사람의 피드백을 통한 강화학습(RLHF, Reinforcement Learning from Human Feedback)을 적용하여 성능을 향상시킬 수 있음 → InstructGPT
- Scaling:
3. Prompting & Training of LLMs
3.1 Prompting: In-context learning
- learning이라는 단어가 있다고 해서 LLM을 pre-training 하거나 fine-tuning 과 같이, 모델의 가중치 파라미터를 업데이트 하는 방법이 아님
- In-context learning은 프롬프트 엔지니어링(Prompt engineering)이라는 기술을 통해 이루어 지며, 프롬프트 내 맥락(in-context)을 LLM이 이해(learning)하고, 적절한 답을 생성하는 것을 말함
- In-context learning은 프롬프트에 몇 개의 예시를 주느냐에 따라 Zero-shot, One-shot, Few-shot으로 나눌 수 있음

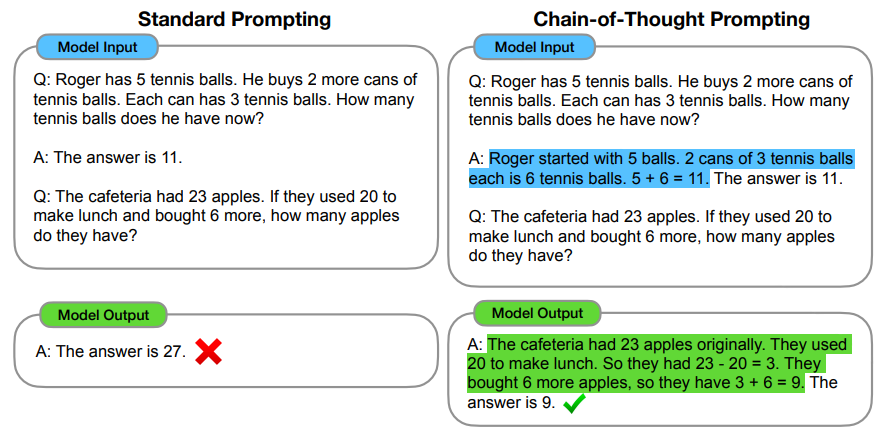
3.2 Prompting: Chain-of-Thought Prompting
- 2022년 1월 구글 브레인팀에서 게재한 논문 “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”(link)에서 소개된 방법
- LLM은 일반적으로 모델의 크기를 늘릴수록 성능이 향상된다고 알려져 있음
- Text Classification(e.g. sentiment analysis)나 Translation 태스크 경우에는 LLM의 크기가 커질수록 성능이 향상됨
- 하지만, multi-step reasoning을 요구하는 태스크들에 대해서는 모델의 크기가 커진다고 해서 성능이 향상되는 것은 아님
- 대표적인 multi-step reasoning 태스크로는 다음과 같이 3가지 태스크가 있음:
- math word problem
- commonsense reasoning
- symbolic reasoning
- CoT Prompting 방법은 중간 추론 단계(intermediate reasoning step)를 프롬프트에 추가함으로써 LLM이 문제에 대한 답을 도출할 수 있도록 prompting하는 것을 말함

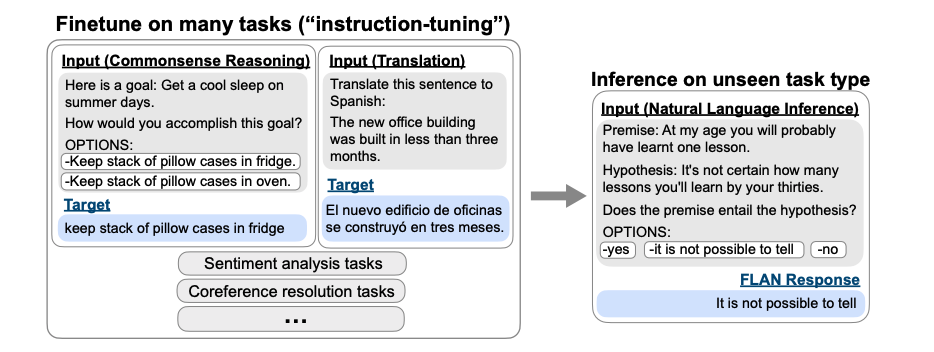
3.3 Fine-Tuning: Instruction Tuning
- 2022년 구글이 ICLR에 게재한 논문 “*Finetuned LANguage Models Are Zero-Shot Learners*”(link)에 제안된 방법 → FLAN
- 3.1에서 살펴본 GPT-3(Language Models are zero-shot Learners, link)에서 소개한 In-context Learning과 FLAN의 차이점은 Fine-tuning에 있음
- FLAN에서 제안한 Instruction Tuning은 다양한 NLP 태스크에 대해 Natural Language Instructions(태스크에 대한 명령 또는 지침)의 헝태로 변형해서 LLM을 fine-tuning 하는 것임
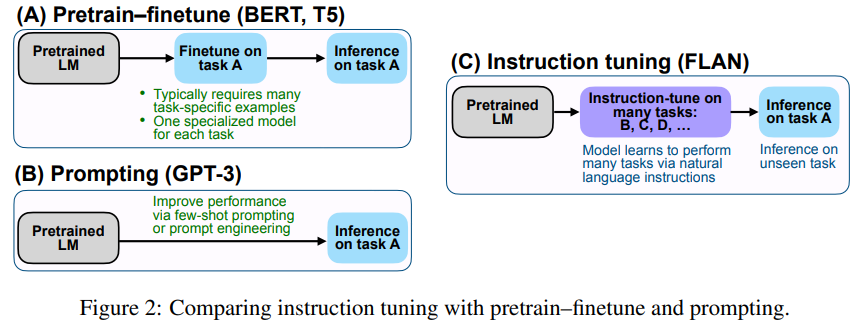
- FLAN은 PLM에 대해, 다양한 NLP 태스크들을 수행할 수 있도록 다음과 같은 형태로 Instruction tuning을 진행함
3.4 Fine-Tuning: RLHF
-
LLM은 엄청난 양의 텍스트 데이터를 사용하여 학습하여, ChatGPT처럼 다양한 태스크에 대해 텍스트를 사람처럼 생성해낼 수 있음
-
하지만, LLM은 다음과 같이 Alignment 문제를 발생시킬 수 있음
- Hallucination: 사실이 아닌 내용이나 말도 안되는 텍스트를 생성해내는 현상
- Biased & Toxic: 편향/독성 데이터로 학습된 LLM일 경우, 이러한 텍스트를 생성하는 현상
-
이를 해결하기 위해, RLHF(Reinforcement Learning from Human Feedback)이라는 Fine-tuning 기법이 제안됨
-
RLHF는 다음과 같이 세 가지 단계로 구성되어 있음:
- Step1: Pretraining a Laguage Model
- Step2: Gathering data and training a reward model
- Step3: Fine-tuning the LM with reinforcement learning
-
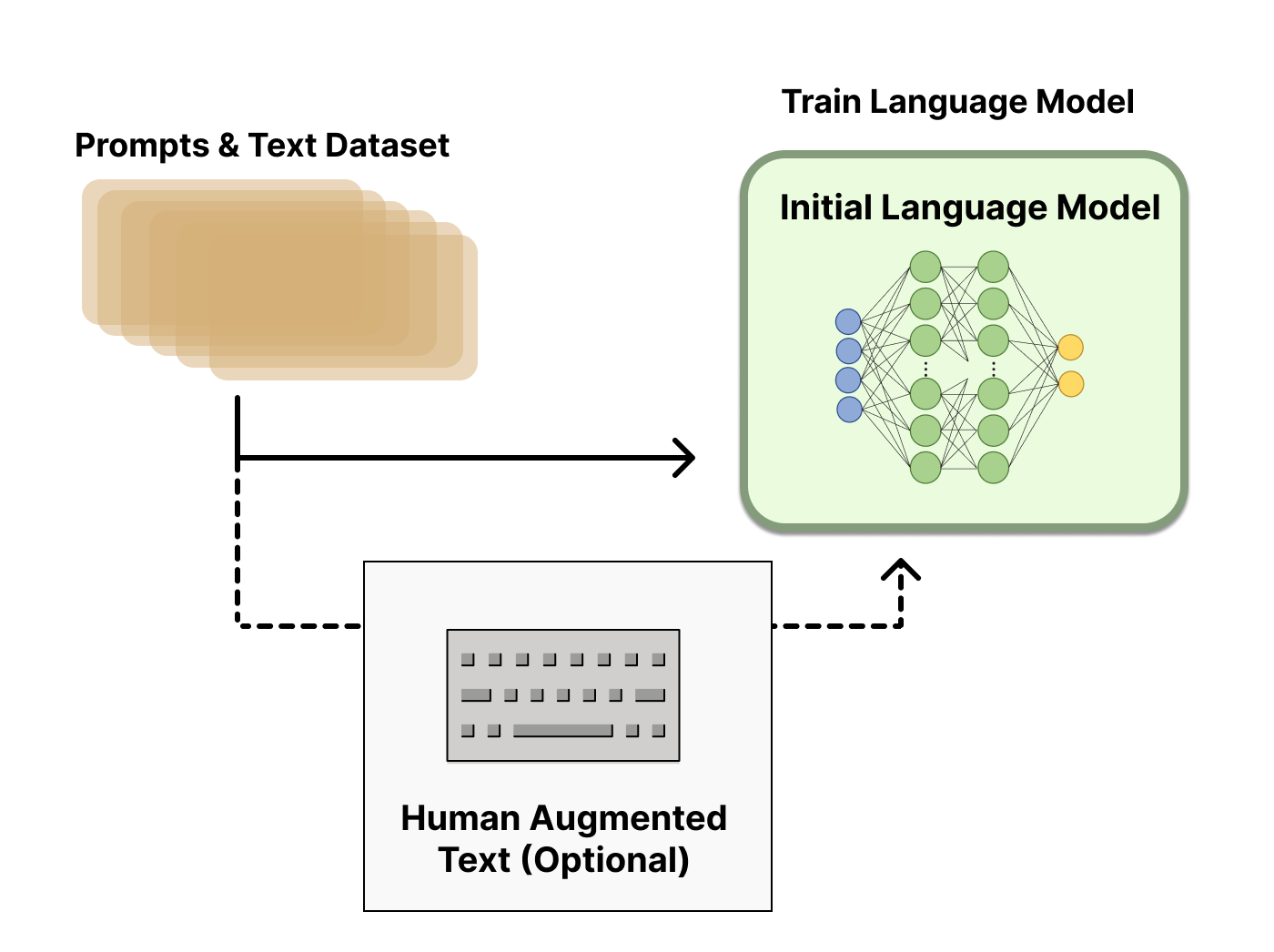
Step 1: Pretraining Language Model
- 기존의 PLM과 동일하게 LM에 대해 Pre-training을 진행함
- RLHF를 하기에 어떤 모델이 가장 좋은지에 대해서는 알려진 바가 없음
- RLHF 학습에 사용하는 옵션들에 대한 design space는 아직 충분히 연구되지 않았기 때문
-
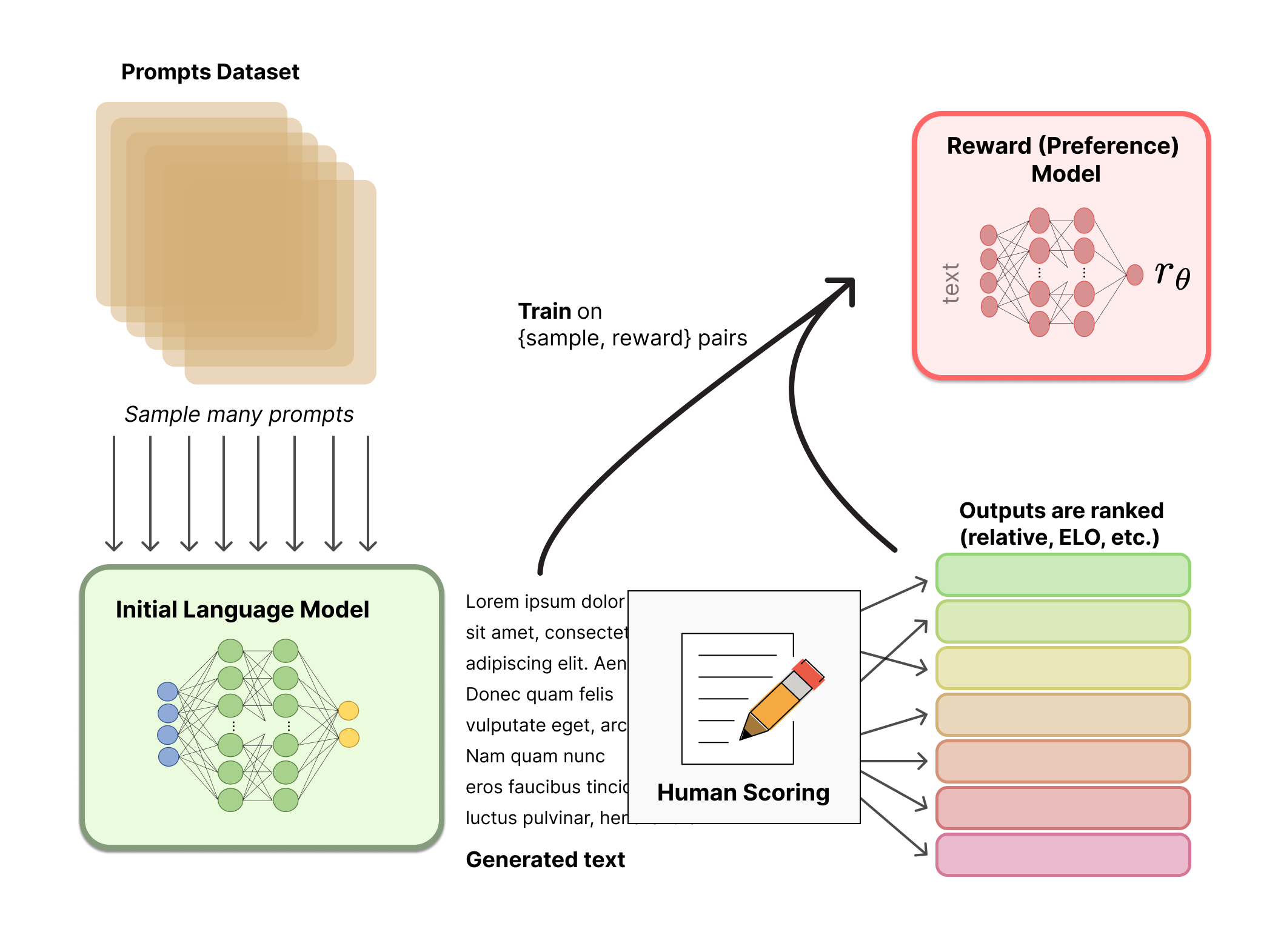
Step 2: Reward Model Training
- Step 1에서 학습된 LM이 생성한 텍스트에 대해, 사람이 직접 점수를 매김 → Human scoring
- 이렇게 만들어진, {텍스트, 리워드} pair를 사용하여 Reward 모델을 학습시킴
-
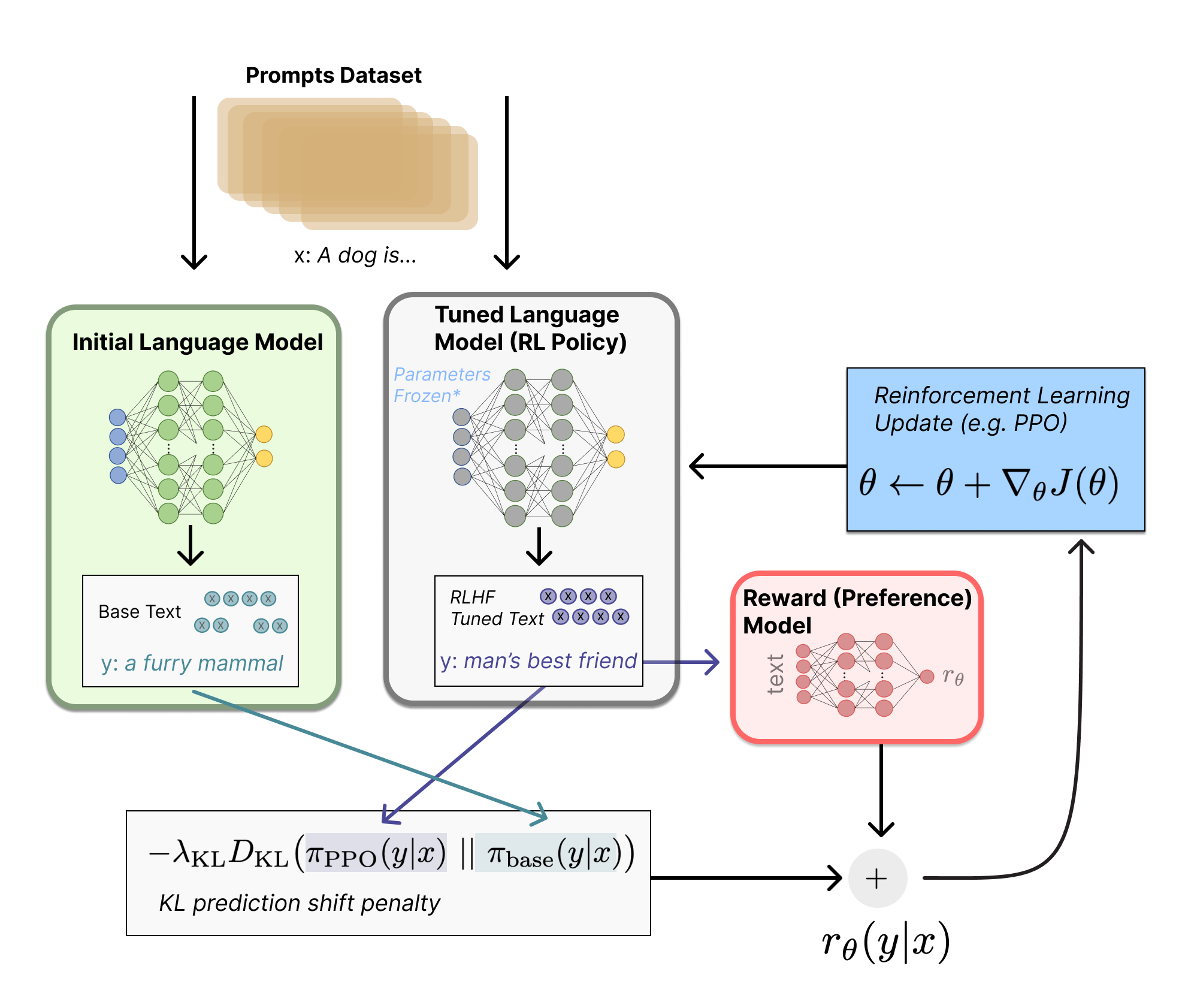
Step 3: Fine-tuning with RL
- ① : Step 1에서의 초기 LM이 생성한 텍스트 $y_1$ 과 RLHF를 통해 fine-tuning될 Policy 모델이 생성한 텍스트 $y_2$가 주어짐
- ② $y_2$ 에 대해 Step 2의 Reward 모델을 통해 점수 $r_\theta$를 구함
- ③ $y_1, y_2$ 두 텍스트를 비교하여 그 차이에 대한 loss를 구함
- 아래의 그림과 같이 KL-divergence를 사용함
- KL-digence를 통해 강화학습 정책(Policy)이 초기 LM에서 너무 벗어나는 것을 방지함
- 이를 통해, LM이 일관성 있는 텍스트를 생성하도록 강제할 수 있음
4. 참고 자료
4.1 논문
- A Survey of Large Language Models (link)
- Scaling Laws for Neural Language Models (link)
- Training Compute-Optimal Large Language Models (link)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (link)
- Finetued Language Models Are Zero-Shot Learners (link)
- Language Models Are Few-Shot Learners (link)
4.2 블로그
4.3 GitHub
- DeepSpeed: https://github.com/microsoft/DeepSpeed
- Megatron-LM: https://github.com/NVIDIA/Megatron-LM
댓글남기기